Why CI/CD pays off before you think you need it
Teams delay pipelines until pain is acute. A thin CI/CD spine early reduces rework, makes security reviewable, and keeps MVPs shippable without heroics.
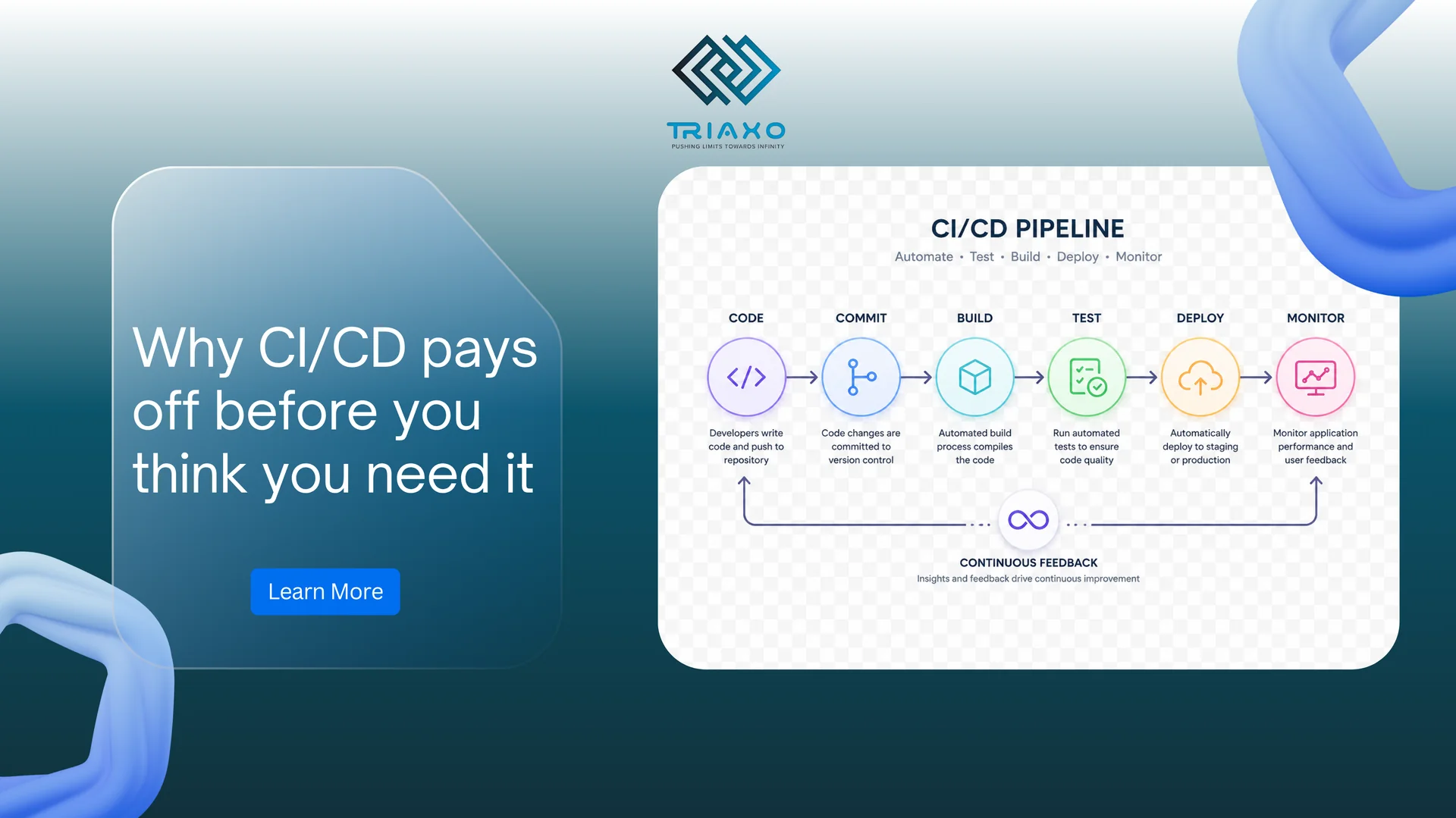
Founders hear CI/CD and picture enterprise overhead. The opposite is true for small teams: without automation, every release depends on one person remembering the migration order at 11 p.m.
The minimum viable pipeline
- Lint + unit tests on every pull request.
- Build container images with immutable tags.
- Deploy to a staging URL automatically.
- Smoke tests that hit health and auth paths.
- Manual approval only for production—never for staging.
That spine takes days, not months. It pays back the first time a bad migration is caught before customers see it, or when a new engineer ships without learning bespoke shell scripts.
Security and compliance ride along
Dependency scanning, secret detection, and IaC policy checks belong in the same pipeline—not a quarterly audit surprise. When SOC2 or HIPAA enters the picture, you already have evidence: build logs, artifact hashes, and who approved prod.
Hero releases do not scale; repeatable releases do.
Triaxo DevOps team
We add progressive delivery—canaries, feature flags, automated rollbacks—when traffic and blast radius justify it. The goal is always the same: make shipping boring in the best way.
Manual deploy runbooks work until they do not—usually during the first holiday on-call rotation or the first new hire asked to "just run the script."
Environments that mean something
Staging should be prod-like enough to catch migration ordering bugs and feature-flag mistakes. Ephemeral preview environments per pull request catch UI regressions early; keep seed data synthetic and free of production PII.
Database changes are releases
Expand-contract migrations: add columns nullable first, dual-write or backfill, then enforce constraints in a later release. Never couple irreversible data transforms with a Friday deploy unless you enjoy weekend restores.
Observability hooks in the pipeline
- Deploy markers in APM so incidents correlate to releases.
- Automated smoke tests post-deploy with automatic rollback on failure.
- Artifact signing and SBOM export for supply-chain questions.
- Change logs attached to tickets—not only git history.
Scaling the pipeline with the team
When headcount doubles, review queue times and flaky tests—they silently tax every sprint. Flake fixes are feature work: they restore trust in green builds, which restores velocity.
We help teams adopt progressive delivery without Kubernetes complexity—managed platforms, trunk-based development, and sane branch policies—so CI/CD investment matches their scale, not a conference slide.
Recent Posts